Класс cBigNumber
для целочисленной арифметики неограниченной разрядности в языке С++
Р.Н. Шакиров
Институт машиноведения УрО РАН
raul@imach.uran.ru
Данный текст является препринтом публикации в журнале "Программные продукты и системы" (С) Р.Н.Шакиров, 2009
Статья на сайте журнала
Арифметические операции над числами неограниченной разрядности – это одна их самых популярных программистских задач. Несмотря на кажущуюся простоту и существование готовых решений, не все могут ими воспользоваться. Иные организации решают эту задачу несколькими различными способами, создаваемые программы могут в тысячи раз отличаться по производительности, часто имеют скрытые ошибки, требуют для правильной работы выполнения множества явных и неявно подразумеваемых технических условий.
Класс cBigNumber выполнен как простое в использовании средство, ориентированное главным образом на платформу Windows. На этой платформе класс имеет сравнимую с лучшими аналогами производительность в диапазоне от 500 до 100,000 двоичных разрядов; при необходимости могут выполняться операции над числами большей разрядности. Реализованы все штатные операции языка С++, извлечение квадратного корня, возведение в степень по модулю и проверка на простоту по методу Миллера. Тестирование класса проведено в автоматическом режиме. Достоверность вычислений обеспечивается встроенными средствами контроля и компенсации ошибок.
Ключевые слова: C++, целочисленная арифметика, неограниченная разрядность, контроль ошибок, компенсация ошибок, метод Миллера, автоматическое тестирование.
1. Особенности класса
cBigNumber
При разработке класса cBigNumber были поставлены следующие основные требования:
1. Корректное выполнение операций на реальных вычислительных устройствах, которые могут работать в нештатном режиме.
2. Оптимальная производительность при проверке на простоту по вероятностному методу Миллера, где требуется выполнять операции с разрядностью от 32 до десятков тысяч бит, включая комбинированные операции над «короткими» и «длинными» числами.
3. Переносимость класса между различными процессорами, операционными системами и трансляторами С++, с возможностью оптимизации под конкретную систему команд.
1.1. Корректное выполнение
операций
Требование корректного выполнения операций подразумевает не только отсутствие арифметических ошибок в самом классе.
Сбои могут возникать в аппаратных вычислительных блоках, если они работают в нештатном режиме, т.е. за пределами оговоренных в документации термических, частотных, радиационных и других условий. Поскольку каждый вычислительный блок имеет индивидуальный запас стабильности, то бывают случаи, когда в нештатном режиме при сохранении общей работоспособности компьютера в отдельных его блоках происходят арифметические ошибки, частота которых зависит от действия нештатных факторов.
К примеру, арифметические ошибки в блоке вычислений с плавающей точкой (FPU - floating point unit) могут остаться незамеченными, т.к. правильная работа FPU непринципиальна для устойчивой работы операционной системы. Поэтому известная программа поиска простых чисел Prime95 [1] перед проведением расчетов тестирует FPU. Тестирование позволяет убедиться в первоначальной работоспособности FPU, но не дает никакой гарантии относительно его дальнейшей работы, если, к примеру, изменится первоначальный тепловой режим. В классе cBigNumber принят другой подход — используется только основное целочисленное ALU. Это ключевой вычислительный блок, периодические арифметические ошибки в котором приводят к краху операционной системы (как только ошибки придутся на квант времени, в котором выполняется операционная система - обычно это дело нескольких миллисекунд, чуть больше на многоядерных и многопроцессорных компьютерах, где операционная система по очереди выполняется на всех вычислительных ядрах). Поэтому мы предполагаем (и основываем на этом предположении архитектуру класса), что если компьютер работает, то и все его целочисленные ALU работают правильно.
Кроме периодических ошибок, вызванных нештатными режимами работы, в компьютерах могут происходить случайные аппаратные сбои, наиболее уязвимой по отношению к которым считается подсистема памяти. Надо отметить, что любые способы компенсации ошибок не дают полной гарантии восстановления данных, хотя вероятность ошибки по известной теореме Шеннона можно сделать сколь угодно малой. Поэтому мы будем полагаться на то, что последствия случайных сбоев в достаточной степени исправляются средствами аппаратного обнаружения и коррекции ошибок, которые собственно для этого и предназначены. Современные микропроцессоры Intel и AMD используют контроль четности в кэше 1-го уровня и коды коррекции ошибок (ECC) в кэшах 2-го и 3-го уровней, а оперативная память может иметь или не иметь ECC – в нашем случае требуется, чтобы она его имела.
Другой внешний источник ошибок — это возможность неверного использования класса прикладным программистом. Наиболее распространенный вид таких ошибок связан с неверным распределением памяти. Поэтому программист, использующий класс cBigNumber, избавлен от необходимости распределять память — в соответствии с рекомендациями объектно-ориентированного программирования (ООП), это делается автоматически в методах класса. Внешняя спецификация класса выполнена в полном соответствии с соглашениями С++ о целочисленных операциях. А внутри класса применяются специальные встроенные средства для отслеживания инвариантов, контроля переполнения буфера и автоматической компенсации возникающих ошибок.
1.2. Производительность
Вопрос о высокой производительности (т.е. скорости выполнения математических операций) уместно ставить в том случае, если все операции выполняются математически корректно - иначе получится соревнование на скорость получения неверного результата. Число ошибок в программе растет с увеличением сложности алгоритма, поэтому для класса cBigNumber выбрано наиболее простое решение - «школьные» алгоритмы выполнения арифметических операций в двоичном варианте. Для увеличения производительности применяется метод умножения Карацубы, деление с таблицей сдвигов и некоторые другие методы, не слишком далеко отходящие от «школьной» методологии (полезно отметить, что метод Карацубы иногда рекомендуют для изучения в школе).
При необходимости, усовершенствованные алгоритмы могут быть отключены в пользу более простых методик. В частности, целочисленное умножение на процессорах Pentium 4 выполняется через ненадежный блок FPU, поэтому для данного процессора эту возможность лучше отключить - тогда вместо аппаратного умножения будут задействованы операции сложения и вычитания. На процессорах следующего поколения (Athlon и Core) целочисленное умножение выполняется в целочисленном ALU, т.е. а) без ущерба для достоверности выполнения операций и б) значительно быстрее — рост производительности по сравнению с вышеупомянутым аддитивным методом составляет до 700%.
Считается, что «школьные» методы дают наилучшую
производительность при размере чисел до 10-20 тысяч двоичных разрядов, а дальше
выигрывает более сложная математика, начиная с методов на основе применения
FFT. Но результаты сравнения в очень
сильной степени зависят от применяемого аппаратного обеспечения и особенностей
программного кода. По данным нашего сравнения на
микропроцессорах AMD, метод умножения Карацубы оказывается быстрее метода FFT
при размере числа до 100 тысяч разрядов и выше. Поэтому мы применяем «школьные»
методы и для чисел большой разрядности.
1.3. Переносимость
Казалось бы, что проблема переносимости не должна существовать в такой хорошо изученной области, как математические вычисления. Но нет – самый известный пакет для работы с большими числами – GMP принципиально ориентирован на UNIX-платформы, причем даже при таком существенном ограничении его разработчики пожаловались на то, что они с 1996 года нашли около 100 ошибок, связанных с применением различных трансляторов: «We are seeing ever increasing problems with mis-compilations of the GMP code... Thus far, we've found on-the-order-of 100 compiler bugs» [2]. В отличие от GMP, класс cBigNumber тестируется и отлаживается на платформе Windows, при соблюдении стандарта C++ ISO/IEC 14882:1998(E) — что позволяет при необходимости компилировать программы на альтернативных UNIX-платформах.
Поскольку на языке С трудно получить максимальную производительность, то в критических по времени операциях вместо С кода может применяться ассемблерный код x386, компилируемый 32-разрядными трансляторами Microsoft Visual C++ и Borland C++ Builder. В дальнейшем возможно создание 64-разрядного ассемблерного кода под соответствующие трансляторы Microsoft. Разработка ассемблерного кода для трансляторов UNIX не рассматривается, как приоритетная цель, т.к. эта задача уже решена во множестве других пакетов.
Исходя из целей ассемблерной оптимизации, для представления длинных целых чисел выбран дополнительный двоичный код. Предполагается, что этот же код применяется и для представления коротких машинных чисел с фиксированной разрядностью, что позволяет проводить комбинированные операции над длинными и короткими числами без преобразования формата. На компьютерах с другим представлением чисел класс работать не будет.
Другое ограничение заключается в том, что отлаженная версия класса ориентирована на применение в однопоточных приложениях. Многопоточная версия существует в виде предварительного варианта, который готовится к тестированию.
2. Правила
применения класса cBigNumber
Класс написан так, чтобы перевод существующих программ на арифметику без ограничения разрядности выполнялся путем простой замены деклараций.
Класс загружается со страницы http://www.imach.uran.ru/cbignum в виде архива Cbignum.zip. Архив следует распаковать в рабочий каталог программы. В проект программы включаются файлы Cbignum.cpp, Cbignumf.cpp, Exarray.cpp, Cbignums.cpp (для потокового ввода-вывода), Prime.cpp (для проверки чисел на простоту).
В тексты программных модулей
добавляются директивы:
#include "Cbignum.h"
#include
"Cbignums.h" (для операций потокового
ввода-вывода)
Неограниченная целая
переменная с нулевым начальным значением объявляется, как
cBigNumber a;
При объявлении переменной можно присвоить короткое начальное значение типа long, а для присваивания длинного начального значения используется конструктор присваивания строки с указанием системы счисления в пределах от 2 до 16. Вместо основания можно указать 0, что подразумевает десятичную, восьмеричную или шестнадцатеричную константу языка C, например:
cBigNumber b ("0x80000000",
0);
Класс реализует все возможности штатной арифметики языка C++ над знаковыми целыми числами, включая арифметические, логические и битовые операции, операции сравнения, арифметические сдвиги, операторы потокового ввода-вывода << и >> со всеми целочисленными модификаторами, а также следующие дополнительные операции:
cBigPow (a,b) Возведение a в степень b (при условии, что хватает памяти).
cBigPowMod (a,b,mod) Возведение a в степень b по модулю mod.
cBigSqrt (a) Целая часть квадратного корня.
В качестве операндов могут применяться длинные числа и короткие числа типа long. Числа типа unsigned long автоматически преобразуются к типу long.
Ряд методов предназначен для оптимизации программ, в их числе:
c.addmul (a,b) Прибавление к c результата умножения a на b
c.setdivmod (a,b) Деление с остатком (частное заносится в c, остаток в a).
c.setsqrtrm (a) Квадратный корень с остатком (корень в c, остаток в а).
На основе методов класса написаны функции для определения простоты числа путем факторизации и по вероятностному методу Миллера.
3.
Производительность класса cBigNumber
Оценки производительности получены под процессорами AMD Athlon/Sempron в 32-разрядном режиме вычислений. Выбор процессоров AMD обусловлен тем, что для класса cBigNumber они обеспечивают более высокую производительность, чем все выпущенные до 2008 года процессоры Intel (см. ниже табл. 1).
Бинарное сложение, вычитание, арифметические сдвиги, операции сравнения и битовые операции реализованы машинно-независимым образом с применением битовых масок. Операции оптимизированы по производительности для чисел размером не менее 200 бит, в этом случае они требуют от 1/5 до 1/2 машинного такта на получение каждого двоичного разряда результата (по данным тестов, проведенных при реализации этих операции). При меньшей разрядности начинают сказываться непроизводительные накладные расходы на выполнения циклов и вызов функций, поэтому производительность несколько снижается. Операции накопления += и -= имеют две реализации — 1) машинно-независимую и 2) оптимизированную на аддитивных операциях ассемблера x386 (рис. 1), в последнем случае один двоичный разряд получается за 1/15 машинного такта при размере чисел не менее 500 бит.
Умножение, деление, возведение в степень и извлечение квадратного корня также имеют две реализации – машинно-независимую с битовыми масками и машинно-зависимую на аддитивных и мультипликативных операциях ассемблера x386. Машинно-независимое умножение оптимизировано для случая, когда размер хотя одного числа не менее 2000 бит, а второго - не менее 200 бит, ассемблерное умножение наиболее эффективно при размере одного числа не менее 1000 бит, второго не менее 10 бит.
Деление, модуль и возведение в степень по
модулю оптимизированы для делителей размером от 500 бит до 1/32 от объема
кэш-памяти процессорного ядра: для кэша в 512 Кбайт оптимальный размер делителя
будет до 120,000 бит. Оптимальный размер аргумента квадратного корня такой же,
как для делителя.
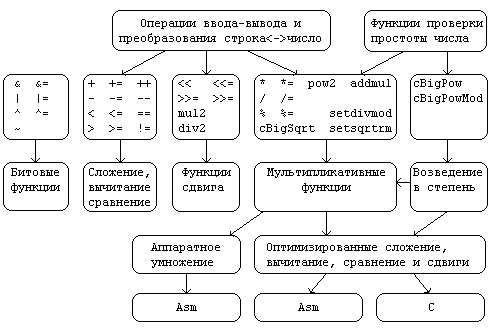
Рис. 1. Структура класса cBigNumber
Оценка производительности дается исходя из известной теоретической оценки сложности алгоритмов [3]. Коэффициенты подобраны нами для ассемблерной реализации по результатам тестов на процессорах AMD Athlon/Semprоn. Коррекция коэффициентов для процессоров Intel и машинно-независимой реализации может быть выполнена по данным табл. 1 (см. ниже).
· умножение: mn/200, где m и n – разрядность операндов в битах, округленная вверх до кратной 32; при разрядности операндов не менее 1600 бит оценка делится на (4/3) log2(n/2000), где n – разрядность меньшего операнда (это эффект метода Карацубы).
· деление: (m-n) n/25, где m и n – разрядность делимого и делителя в битах;
- квадратный корень: n2/120, где n - разрядность числа;
· возведение в степень по модулю: n2m/17, где n – разрядность показателя, m – делителя;
·
ввод и преобразование строки: n2/400, n - разрядность
числа; для числа разрядностью более 100,000 бит оценка делится на (4/3)
log2(n/20000).
·
вывод и преобразование в строку: n2/75;
Результаты выполнения основных тестов на различных процессорах приведены в табл. 1. Колонка asm соответствует приведенным выше оценкам. В колонке NTL для сравнения приведены результаты известной библиотеки неограниченных чисел [4], которая использует схожую алгоритмическую базу. В колонке C++ приведены результаты машинно-независимого кода.
Тест Умножение Деление Степень по модулю
~250000*65000 бит ~250000/65000 бит ~45%25000 бит
Процессор asm
NTL C++ asm
NTL C++ asm
NTL C++
-----------------------------------------------------------------------------
Pentium
III/933 55 214 494 970 1056
2005 2906 3494 8578
Pentium 4C/2400 45
64 245 611
278 981
2343 906
4297
Athlon
900 29 135
469 543
705 1729
1892 2123 8051
Athlon
XP 2500+ 14 66
230 263
345 900 906 1047 4094
Athlon 64 X2 3800+ 11 56 175 236
298 697 813 969 3172
Core
Duo T2500 28 70 217
359 241 786 1437
844 3765
Core 2 Duo E6420 23 70
175 313 205 606
1234 735 2937
Табл.1. Время выполнения тестов в мс
Отметим, что в варианте для Windows библиотека NTL не использует машинно-зависимые операции, вместо это проводится глубокая оптимизация С кода с применением FPU. Оптимизация дает хороший эффект на процессорах Intel, для которых она, по-видимому, и проводились. Операции вычисления квадратного корня и ввода-вывода исключены из сравнения, поскольку в библиотеке NTL они выполняются по неоптимальным алгоритмам — на 2 порядка медленнее, чем в классе cBigNumber.
4. Распределение
памяти в классе cBigNumber
Реализация класса не зависит от фактической разрядности машинного слова, т.к. для хранения длинного числа отводится переменное число слов.
Конструктор класса создает объект с нулевым значением без выделения динамической памяти (это целесообразно при создании разреженных массивов из неограниченных чисел). Память выделяется при первом присваивании с учетом возможности дальнейшего увеличения числа. В среднем, резервируется 33% от минимально необходимого объема памяти; если этой памяти не хватит, то проводится повторное резервирование. Минимальное количество слов, отводимых под число – около 25. При уменьшении числа вся высвобожденная память остается в резерве. При указанном способе выделения общее число распределений памяти под число пропорционально логарифму его максимального размера в машинных словах.
Высвобождение памяти выполняется в деструкторе класса, который автоматически удаляет объект класса при выходе из области видимости. Но если объект класса создавался неявным образом для хранения результата операции, то он остается в памяти в качестве буфера для результата последующих операций.
5.
Встроенные средства контроля и коррекции ошибок
Язык С++ сам по себе мало подходит для разработки надежных программ, но он достаточно гибок для того, чтобы соответствующие средства можно было реализовать путем его расширения.
Для распределения памяти в закрытой части класса задействованы разработанные нами шаблоны динамических массивов [5]. Шаблоны обеспечивают два режима распределения памяти – автоматический для массивов неограниченного размера и ручной со страховкой, когда программист задает требуемые размеры массива, а программа в процессе выполнения автоматически отслеживает ошибки выхода индекса за границу массива. В классе cBigNumber по соображениям производительности применяется ручное распределение памяти. В этом случае возможны ошибки распределения памяти, из-за которых в определенных ситуациях будут возникать ошибки индексации, более известные как ошибки «переполнения буфера» Но потенциально неверный результат получен не будет, т.к. при ошибке индексации программа завершит работу с выдачей диагностики.
Для увеличения производительности предусмотрена возможность отключения контроля индексов, при этом шаблон автоматически добавляет к массиву дополнительный страховочный элемент. Данная страховка не равноценна контролю индексов, т.к. она компенсирует только один распространенный класс ошибок – обращение к элементу, следующему за последним в массиве.
Другой метод динамического контроля состоит в проверке предусловий и постусловий операций во внешних и внутренних методах класса. В качестве примера предусловия можно привести проверку деления на 0, а в постусловии обычно проверяется знак результата операции, т.к. ошибки при вычислениях в дополнительном коде довольно часто приводят к его искажению.
6. Тестирование класса
cBigNumber
Для тестирования класса написаны программы Arifexp и Miller, которые проводят операции с длинными числами и проверяют результат по методам обратной и альтернативной прямой операции (большинство операций реализовано в классе несколькими различными способами, поэтому можно проводить проверку по методу независимых алгоритмов).
В программу Arifexp встроен генератор примеров, адаптированный для тестирования длинных чисел. Поскольку традиционный генератор с равномерным распределением в нашем случае неэффективен [6], то распределение «подправлено» в пользу чисел, которые могут быть источниками ошибок, исходя из знаний об особенностях алгоритмов.
С помощью программы Arifexp вычислительное ядро класса протестировано на 10 миллиардах псевдослучайных примеров с разрядностью от 1 до 12,000,000 бит. Программа Miller перебрала более миллиарда чисел малой разрядности для проверки таблиц факторизации. По статистике ошибок, базовые арифметические операции были отлажены в 2003 году, возведение в степень по модулю и проверка на простоту – в 2005 году, умножение по методу Карацубы – после его реализации в 2007 году. Результаты тестирования показали высокую эффективность встроенных средств контроля и коррекции ошибок – ими обнаруживается около 55% от общего числа выявленных ошибок (12 из 22).
Наибольшее число ошибок – 11 было обнаружено при контроле индекса. Если его отключить, то 6 ошибок никак себя не проявят, т.к. они полностью компенсируются по методу резервного элемента, 2 ошибки приведут к аварийному завершению программы без выдачи результата, 3 ошибки теоретически могут привести к выдаче неверного результата, но при тестировании этого не происходит, т.к. ошибки являются крайне маловероятными. И только одна ошибка, обнаруженная при проверке знака в постусловии, была арифметической. Приведенная статистка хорошо отражает природу современного программного обеспечения – количество скрытых ошибок может в несколько раз превышать число выявленных ошибок, в нашем случае некоторые скрытые ошибки стали явными благодаря применению специальных средств отладки.
Оставшиеся 10 ошибок были арифметическими и распределились так – 4 ошибки обнаружены при автоматическом тестировании, 3 ошибки обнаружены при анализе кода класса и 3 ошибки выявлены бета-тестерами в 2005 года в функциях возведения в степень и проверки на простоту, для которых в то время не было реализовано автоматическое тестирование. Таким образом, общая эффективность автоматических методов выявления ошибок составила около 73% (16 из 22).
Заключение
Класс cBigNumber прост в использовании и обладает высокой производительностью на платформе Windows благодаря применению встроенного ассемблера. Сильные стороны класса – простые алгоритмы, использование наиболее надежных аппаратных средств и повышенная достоверность результатов вычислений.
Литература
1.
Prime95
download page: http://www.mersenne.org/freesoft.htm
2.
The
GNU MP Bignum Library: http://www.swox.com/gmp/
3.
Дональд Э. Кнут. Искусство программирования, т.2,
гл.
4.
A
Library for doing Number Theory: http://www.shoup.net/ntl/
5.
Р.Н.Шакиров. Шаблоны для организации контроля индексов
в программах на языках С++ и С // В сб. трудов международной
научно-технической конференции IEEE AIS-03 и CAD-2003 (Дивноморское,
3-10 сентября 2003). М.: Физматлит, 2003. Т.2, С.191-207.
http://imach.uran.ru/exarray/papers/ex2003p.htm
6. Р.Н.Шакиров. Принципы разработки межплатформенного класса cBigNumber для реали-зации арифметических операций над целыми числами неограниченной разрядности // Проблемы компьютерной безопасности и криптографии: Докл. 4 сибирской научной школы-семинара с межд. участием SIBERCRYPT'05 (Томск, 10-12 сентября 2002). Вестник Томского государственного университета. Приложение. Материалы международных, всероссийских и региональных научных конференций симпозиумов, школ проводимых в ТГУ, 2005. №14. С.191-195. http://www.imach.uran.ru/cbignum/papers/cb2005p.htm